
Перш ніж зануритися в технічні процедури, зупинімося на хвилинку на фундаментальному питанні: коли слід використовувати файл CSV, а коли краще покластися на електронну таблицю Excel (XLSX)? Це не простий вибір. CSV — це чистий текстовий файл, універсальний, ідеальний для переміщення великих обсягів необроблених даних між різними системами. Натомість файл Excel — це справжнє робоче середовище, яке складається з формул, графіків та розширеного форматування. Розуміння цієї відмінності — це перший крок до перетворення ваших даних на ефективні бізнес-рішення, що дозволить уникнути розчарувань і втрати часу. У цьому посібнику ви не тільки дізнаєтеся про відмінності, але й навчитеся професійно імпортувати, очищати та експортувати дані, гарантуючи, що ваші аналізи завжди базуються на міцній і надійній основі.
Вибір між CSV і Excel — це не просто технічне питання, а стратегічне рішення. Використання правильного формату з самого початку економить ваш дорогоцінний час і дозволяє уникнути непотрібних помилок.
Уявіть собі файл CSV як список покупок: він містить тільки найважливішу інформацію, написану чітко і зрозуміло для всіх. Це ідеальний формат для експорту даних з бази даних, електронної комерції або програмного забезпечення для управління. Ніяких надмірностей, тільки чисті дані.
Файл Excel (XLSX), навпаки, схожий на інтерактивну кулінарну книгу. Він не просто перелічує інгредієнти, а й надає інструкції, фотографії готової страви і, можливо, автоматичний калькулятор порцій. Він стає обов'язковим вибором, коли потрібно проаналізувати ці дані, створити візуалізації або поділитися звітом, який має бути відразу зрозумілим для вашої команди.
Для більшої наочності наведемо таблицю, в якій порівняно ці два формати.
Формат CSV ідеально підходить для конкретних ситуацій, де простота і сумісність мають першочергове значення.
Excel стає вашим найкращим другом, коли вам потрібно не тільки зберігати дані, але й працювати з ними, моделювати їх і змушувати їх говорити.
Вибір Excel означає перехід від простого збору даних до їх перетворення на знання. Це вирішальний крок, який перетворює цифри на бізнес-рішення.
Файл XLSX — це найкращий вибір, коли вам потрібно:
Розуміння цієї відмінності є першим і найважливішим кроком для перетворення необроблених даних у корисну інформацію.
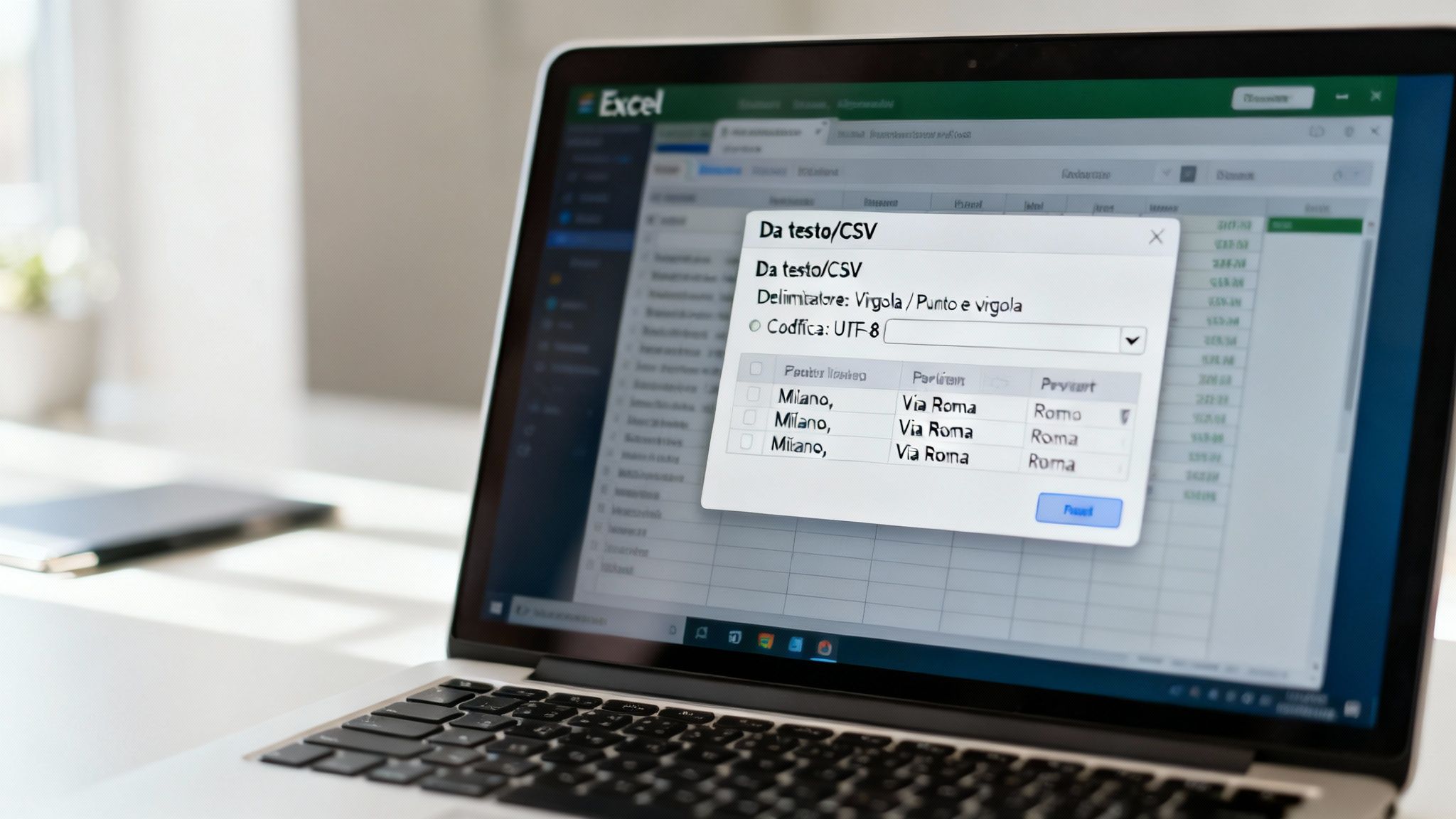
Відкрити файл CSV в Excel простим подвійним клацанням? Це майже завжди погана ідея. Таким чином ви дозволяєте Excel самостійно вгадувати структуру ваших даних, і результат часто буває катастрофічним: зіпсоване форматування, обрізані числа та незрозумілі символи.
Щоб отримати повний контроль, потрібно піти іншим шляхом. Перейдіть на вкладку «Дані» на панелі інструментів Excel і знайдіть опцію «З тексту/CSV». Ця функція — не просто «відкрити файл», а справжній інструмент імпорту, який дає вам повний контроль і дозволяє вказати Excel, як саме інтерпретувати кожну частину вашого файлу.
Це перший, фундаментальний крок для перетворення простого текстового файлу в чітку таблицю, готову до аналізу.
Після запуску процедури першим важливим вибором є вибір роздільника. Це символ, який відокремлює одне значення від іншого у вашому CSV-файлі. Якщо ви помилитеся тут, всі дані опиняться в одному, непридатному для використання стовпці.
Найпоширенішими є:
На щастя, інструмент імпорту Excel надає попередній перегляд у режимі реального часу. Спробуйте вибрати різні роздільники, поки не побачите свої дані, упорядковані в ідеальні стовпці. Цей простий крок вирішує 90% проблем з імпортом.
Чи траплялося вам коли-небудь імпортувати файл і бачити, як слова з діакритичними знаками, наприклад «Perché», перетворюються на «Perch�»? Ця плутанина виникає через неправильне кодування символів. Простіше кажучи, кодування — це «мова», яку комп'ютер використовує для перетворення байтів файлу в символи, які ми бачимо на екрані.
Нечитабельні дані – це марні дані. Вибір правильного кодування – це не технічна деталь, а необхідна умова для забезпечення цілісності вашої інформації.
Ваша мета — знайти кодування, яке правильно відображає всі літери, особливо ті, що мають діакритичні знаки, або спеціальні символи. У вікні імпорту знайдіть випадаюче меню «Джерело файлу» і спробуйте кілька варіантів:
І тут попередній перегляд — ваш найкращий друг: переконайтеся, що все читається, перш ніж підтверджувати.
Ось класична і дійсно підступна помилка. Подумайте про коди, такі як поштові індекси (наприклад, 00184 для Рима) або коди продуктів (наприклад, 000543). За замовчуванням Excel розглядає їх як числа і, щоб «очистити» їх, видаляє нулі перед ними, перетворюючи «00184» на просте «184». Проблема полягає в тому, що таким чином дані пошкоджуються.
Щоб цього уникнути, на останньому кроці майстра Excel покаже вам попередній перегляд стовпців, даючи вам можливість визначити формат для кожного з них. Тут ви повинні вжити заходів: виберіть стовпець, що містить поштові індекси або інші числові коди, і встановіть тип даних на «Текст». Таким чином, ви змусите Excel обробляти ці значення як рядки символів, зберігаючи початкові нулі.
Навіть коли ви дотримуєтеся ідеальної процедури, іноді дані здаються непідконтрольними. Настав час вирішити реальні проблеми, які виникають під час роботи з «брудним» або нестандартним файлом CSV Excel.
Часто проблеми не видно неозброєним оком. Можливо, ви маєте справу з невидимими пробілами в кінці коду продукту, які заважають формулі CERCA.VERT працювати. Або з даними, які розтягуються на кілька рядків, але логічно належать до однієї комірки. Саме такі деталі перетворюють п'ятихвилинне імпортування на ціле полудень розчарування.
Однією з найпоширеніших проблем є автоматичне перетворення даних програмою Excel. Програма намагається бути «розумною», але часто в результаті пошкоджує інформацію.
Подумайте про дуже довгі числові коди продуктів, такі як штрих-коди. Excel може інтерпретувати їх як наукові числа, перетворюючи 1234567890123 в 1,23E+12 і втрачаючи кінцеві цифри. Ще одним класичним прикладом є обробка дат: якщо ваш CSV-файл використовує американський формат (ММ/ДД/РРРР), Excel може інтерпретувати його по-своєму, помінявши місцями місяці та дні.
Щоб уникнути таких катастроф, рішення майже завжди одне й те саме: скористайтеся майстром імпорту. Цей екран дозволяє вам задати правильний формат для кожного стовпця, перш ніж Excel встигне нашкодити.
Налаштування стовпця як «Текст» є вирішальним кроком для захисту кодів, ідентифікаторів або будь-яких чисел, які не повинні використовуватися для математичних обчислень.
Практичний приклад цієї проблеми ми часто бачимо на прикладі італійських публічних даних. Архів італійських муніципалітетів, що налічує 7 904 об'єкти, є ідеальним прикладом для вивчення. Якщо спробувати імпортувати файл CSV в Excel без попередніх заходів, телефонні коди, такі як «011» для Турина, перетворюються на «11», втрачаючи початкову нуль. Ці дані стають непридатними для будь-якої системи, яка вимагає правильного формату. До речі, той самий архів показує, що 98% муніципалітетів мають менше 15 000 жителів, що є фундаментальною інформацією для демографічного аналізу, яка залежить від бездоганного імпорту даних. Більше інформації про цей цінний ресурс ви можете знайти в повній базі даних італійських муніципалітетів.
Іноді проблеми виникають тільки після завантаження даних. Не хвилюйтеся, ось кілька швидких рішень для найпоширеніших випадків:
Скасувати.Простір у новій колонці, щоб видалити всі зайві пробіли на початку, в кінці або між словами.ВІЛЬНА призначена саме для їх видалення.ЗАМІНИТИ для заміни символу нового рядка (часто КОД.ХАРАКТЕРИСТИКА(10)) простим пробілом.Опанування цих технік очищення перетворює управління даними з перешкоди на конкурентну перевагу. Замість того, щоб боротися з файлами, ви починаєте змушувати їх працювати на вас.
Вміння вирішувати ці проблеми дозволяє вам впоратися навіть з найхаотичнішими CSV-файлами, гарантуючи, що ваші аналізи завжди базуються на надійній базі даних.
Якщо ви щотижня вручну імпортуєте та очищаєте один і той самий звіт у форматі CSV, ви марнуєте дорогоцінний час. Настав час відкрити для себе Power Query — інструмент для перетворення даних, інтегрований в Excel, який можна знайти на вкладці «Дані» > «Отримати та перетворити дані». Це не просто імпортер, а інтелектуальний реєстратор.
Power Query відстежує та запам'ятовує кожну дію, яку ви виконуєте з даними: видалення стовпців, зміну форматів, фільтрування рядків. Весь процес очищення зберігається як «запит». Наступного разу, коли ви отримаєте оновлений звіт, вам достатньо буде лише одного кліка на кнопку «Оновити», щоб миттєво повторити всю послідовність дій.
Такий підхід не тільки позбавляє від багатогодинної рутинної роботи, але й гарантує абсолютну узгодженість, повністю виключаючи ризик людських помилок.
Уявімо типовий сценарій: щотижневий звіт про продажі у форматі CSV. Замість того, щоб відкривати його безпосередньо, скористайтеся меню Дані > З тексту/CSV, щоб запустити Power Query. Відкриється нове вікно, редактор Power Query.
Звідси ви починаєте моделювати дані. Кожна дія реєструється в панелі «Застосовані кроки» праворуч:
Після того, як дані очищені та структуровані відповідно до ваших побажань, натисніть «Закрити та завантажити». Excel створить новий аркуш із таблицею, пов'язаною з вашим запитом. Наступного тижня вам потрібно буде лише замінити старий файл CSV новим (зберігаючи те саме ім'я та розташування), відкрити файл Excel і перейти до «Дані» > «Оновити все». Ви побачите, як таблиця заповнюється новими даними, вже очищеними та відформатованими.
Ця інфографіка точно показує процес очищення, який автоматизує Power Query.
Перегляд цього потоку допомагає зрозуміти, як кожен зареєстрований крок сприяє створенню надійного та повторюваного процесу імпорту даних.
Справжня потужність Power Query проявляється, коли ви використовуєте його для підключення до динамічних джерел даних безпосередньо в Інтернеті. Згадайте платформу «Noi Italia» від Istat, яка пропонує понад 100 економічних показників у форматі CSV. Ви можете створити запит, який безпосередньо підключається до цих даних. Замість того, щоб щомісяця вручну завантажувати файл, достатньо оновити запит, щоб автоматично імпортувати, наприклад, найновіші дані про рівень зайнятості. Щоб дізнатися більше, ви можете ознайомитися з показниками Istat безпосередньо на їхньому порталі.
Автоматизація за допомогою Power Query — це не тільки економія часу. Це створення надійної системи, яка дозволяє вам завжди довіряти своїм даним.
Цей підхід змінює спосіб взаємодії з зовнішніми даними. Щоб інтегрувати ці потоки з іншими корпоративними системами, дізнайтеся, як API Electe зв'язок між різними платформами, виводячи автоматизацію на новий рівень.
На завершення, ось короткі відповіді на найпоширеніші запитання, що виникають при роботі з файлами CSV та Excel, щоб розвіяти сумніви, які можуть заважати вам, і допомогти вам працювати з більшою впевненістю.
Це відбувається тому, що Excel за замовчуванням вважає, що стовпець, заповнений цифрами, є числовим, і «очищає» нулі, які вважає зайвими. Таким чином, поштовий індекс «00123» стає просто «123».
Щоб цього уникнути, скористайтеся майстром імпорту (Дані > З тексту/CSV). Коли вам буде запропоновано визначити тип даних для кожного стовпця, виберіть «проблемний» стовпець і встановіть для нього тип «Текст». Таким чином, ви даєте Excel команду не робити припущень і обробляти ці значення як символьні рядки.
Це головна ознака неправильного роздільника. Ваш CSV-файл використовує роздільник (можливо, крапку з комою), який Excel не розпізнав автоматично, часто через «сліпе» імпортування подвійним клацанням.
Рішенням є функція «З тексту/CSV». Цей інструмент дає вам можливість самостійно вказати правильний роздільник: кому, крапку з комою, табуляцію чи інше. Коли ви побачите, що стовпці правильно розділилися в попередньому перегляді, значить ви знайшли правильне налаштування.
Стандартний формат «CSV» є застарілим і може виникнути проблема з спеціальними символами або літерами з діакритичними знаками. Існує ризик, що при відкритті файлу на іншому комп'ютері ці символи будуть замінені незрозумілими знаками.
Вибір «CSV UTF-8» гарантує універсальну сумісність. Це стандарт кодування, який забезпечує правильне відображення таких символів, як «à», «è», «ç» у будь-якій операційній системі та будь-якій мові.
На практиці, якщо ваші дані не є лише текстом і цифрами на простій англійській мові, завжди використовуйте лише CSV UTF-8.
Щоб найкраще управляти своїми даними, запам'ятайте ці три золоті правила.
Ви імпортували, очистили та проаналізували дані. Момент, який може врятувати або зруйнувати години роботи, — це збереження. Відкрити файл CSV, попрацювати з ним, додавши формули та графіки, а потім натиснути «Зберегти» і перезаписати все плоским текстовим файлом означає втратити все. CSV за своєю природою зберігає тільки необроблені дані активного аркуша.
Коли аналіз завершено і ви хочете зберегти всі деталі, є тільки один розумний вибір: зберегти файл у рідному форматі Excel, XLSX. Цей формат є надійним «контейнером» для всієї вашої роботи.
Запам'ятайте це золоте правило: CSV використовується для передачі необроблених даних, аXLSX — для їх обробки та зберігання. Розуміння цієї відмінності заощадить вам величезну кількість часу.
Вміння працювати з файлами CSV в Excel є основною навичкою, але це лише початок. Ви навчилися правильно імпортувати дані, очищати їх та автоматизувати процеси, створивши міцну та надійну основу для своїх аналізів. Це перший, найважливіший крок для перетворення необроблених цифр у бізнес-рішення.
Тепер, коли ваші дані готові, настав час розкрити їх справжній потенціал. Платформи аналізу на основі штучного інтелекту, такі як Electe естафету там, де Excel зупиняється, перетворюючи ваші очищені файли в точні прогнози, сегментацію клієнтів і стратегічні інсайти, без необхідності писати жодної формули. Використовуйте синергію між цими інструментами: використовуйте Excel для підготовки і довіртеся Electe дізнатися, що насправді ховається у ваших даних. Почніть перетворювати свою інформацію в конкурентну перевагу.
Electe, наша платформа аналізу даних на основі штучного інтелекту для малих та середніх підприємств, бере саме ці очищені CSV-файли та перетворює їх на прогнозні аналітичні дані та автоматичні висновки за допомогою декількох кліків.
Дізнайтеся, як це працює, і почніть безкоштовне тестування →

.svg)
.svg)
.svg)






