Повний посібник з програмного забезпечення для бізнес-аналітики для МСП
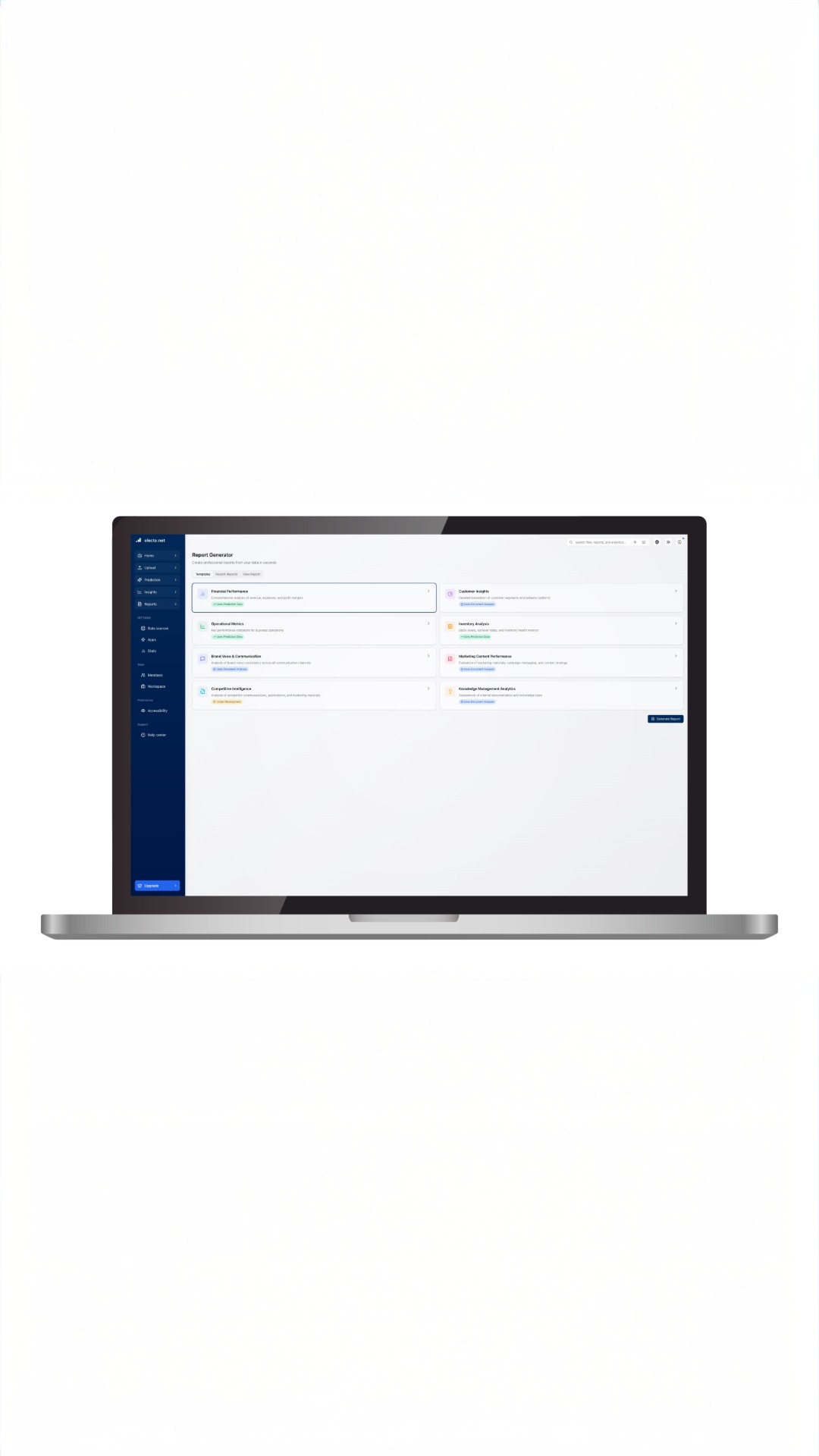
60% італійських МСП визнають, що мають критичні прогалини в підготовці даних, 29% навіть не мають спеціальної цифри - в той час як італійський ринок бізнес-аналітики зросте з $36,79 млрд до $69,45 млрд до 2034 року (CAGR 8,56%). Проблема не в технології, а в підході: малі та середні підприємства тонуть у даних, розкиданих між таблицями CRM, ERP, Excel, не перетворюючи їх на рішення. Це стосується як тих, хто починає з нуля, так і тих, хто хоче оптимізувати. Критерії вибору, які мають значення: зручність використання без місяців навчання, масштабованість, яка зростає разом з вами, інтеграція з існуючими системами, повна сукупна вартість володіння (впровадження + навчання + обслуговування) порівняно з вартістю самої лише ліцензії. 4-крокова дорожня карта - вимірювані SMART-цілі (зменшити відтік на 15% за 6 місяців), чисте мапування джерел даних (сміття на вході = сміття на виході), навчання команди культурі даних, пілотний проект з безперервним циклом зворотного зв'язку. ШІ змінює все: від описової BI (що сталося) до доповненої аналітики, яка виявляє приховані закономірності, предиктивної, яка оцінює майбутній попит, прескриптивної, яка пропонує конкретні дії. Electe демократизує цю силу для МСП.







.jpeg)

.png)
.jpeg)
.jpeg)
.jpeg)


.jpeg)

.jpeg)



.jpeg)
.jpeg)
.jpeg)
.jpeg)
.png)
.jpeg)



.jpeg)